
이 글은 원티드의 ‘‘프리온보딩 백엔드 챌린지 12월 - 백엔드 인프라 설계 w AWS”
3번째 강의를 듣고 작성한 글입니다.
정확하지 않은 정보가 있다면 댓글 부탁드립니다.
AWS 인프라의 전체적인 모습
인프라 관련 요소들 AWS API Gateway, AWS S3, AWS ELB, AWS CloudFront, AWS Secret Manager, 스냅샷
컴퓨팅 파워(서버) AWS EC2, AWS Elastic Beanstalk, AWS ECS, AWS Fargate, AWS Lambda(Serverless)
Database AWS RDS, AWS DynamoDB, AWS ElastiCache
Message Queue - 대용량 데이터 처리 시 필요 AWS SQS, AWS MSK, AWS Kinesis
AWS Database
AWS RDS (Relational Database Service)
클라우드에서 관계형 데이터베이스를 간편하게 설정, 운영 및 확장할 수 있는 관리형 서비스 모음
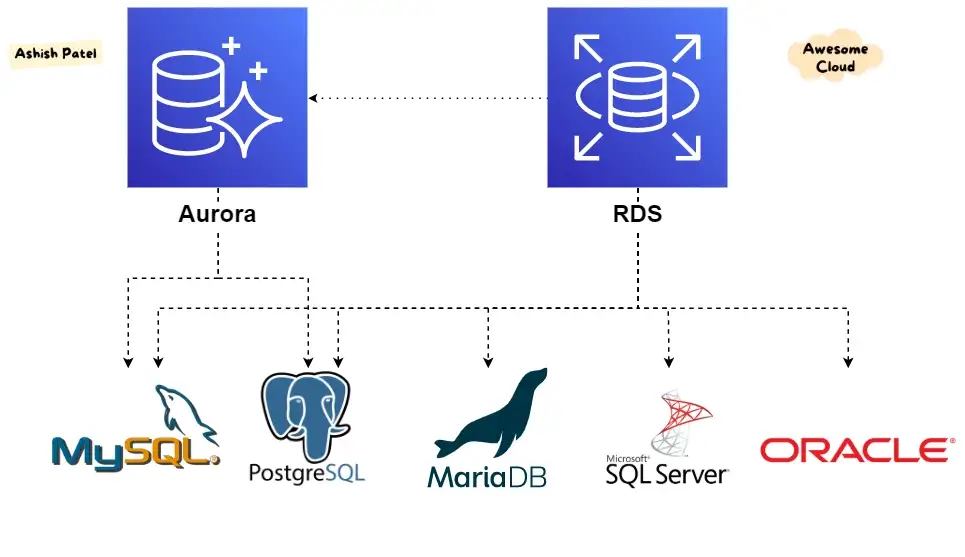
- MySql, PostgreSql, MariaDB, SQL Server, Oracle을 지원한다.
- 그 중에서도 MySql, PostgreSql은 Aurora와 호환된다.
주요 기능
- RDS 백업 : 자동백업, DB 스냅샷(수동적으로 DB를 백업해놓는 것)
- 멀티 AZ : 두개 이상의 AZ에 걸쳐 DB를 구축하고 원본과 다른 DB(standby)를 자동으로 동기화(Sync), 읽기 전용 복제본 (여러 곳에 복제, 서로 동기화되게 한다)
- CloudWatch 연동 : DB 인스턴스의 모니터링(디테일 모니터링, CPU, Storage 사용량, 그 이외의 Error Log)
AWS Aurora
튜닝한 데이터베이스 AWS만의 관계형 데이터베이스로써, 기존의 소스를 커스터마이징하여 AWS에 최적화시킨 것
- 기존 RDS는 EBS를 사용하지만, Aurora는 NVMe SSD 드라이브 위에 구축되어서 훨씬 빠르다. (MySql보다 최대 5배 많은 처리량과 PostgreSQL보다 3배 많은 처리량)
- 대역폭이 크다. (한 번에 처리할 수 있는 양이 훨씬 많다.)
- 서버리스 기능과 Auto Scailing을 기본적으로 지원한다.
- 서버리스 기능 : 서버가 항상 켜져있지 않은 DB (요청만 처리를 해주고 인스턴스는 AWS에서 관리, 개발 서버에서 테스트용 DB가 필요할 경우 쓰는 만큼만 지불되도록 하기 위해 사용, 일반 Aurura보다 약간 느리다.)
- 대신 조금 비싸다. (r6g.2xlarge 기준 MySQL : $1.02 / Aurora $1.253)
- 데이터가 SSD에 저장되기 때문에 거의 Realtime이 보장된다.
AWS DynamoDB
원전관리형 NoSQL 데이터베이스 서비스로서 원활한 확장성과 함께 빠르고 예측 가능한 성능을 제공한다.
- 서버리스이므로, 따로 유지비용 없이 사용한 만큼만 지불
- 보조 인덱스를 통해 빠른 조회를 지원
- 서버리스(람다) 서버와의 궁합이 매우 잘 맞는다.
- 람다를 사용하면 커넥션이 많아질 수 있는데 이 때 RDB는 커넥션 관리(Max Connection 설정)를 따로 해줘야 하지만, DynamoDB는 커넥션이 아예 없기 때문에 많은 람다 서버의 요청을 받을 수 있다. (DynamoDB는 HTTP 통신으로 이루어지기 때문이다. - 다른 DB들은 TCP Connection 기반)
- 순서와 상관없이 비동기적으로 처리된다.
AWS Elasticache
클라우드에서 분산된 인 메모리 데이터 스토어 또는 캐시 환경을 손쉽게 설정, 관리 및 확장할 수 있는 웹 서비스
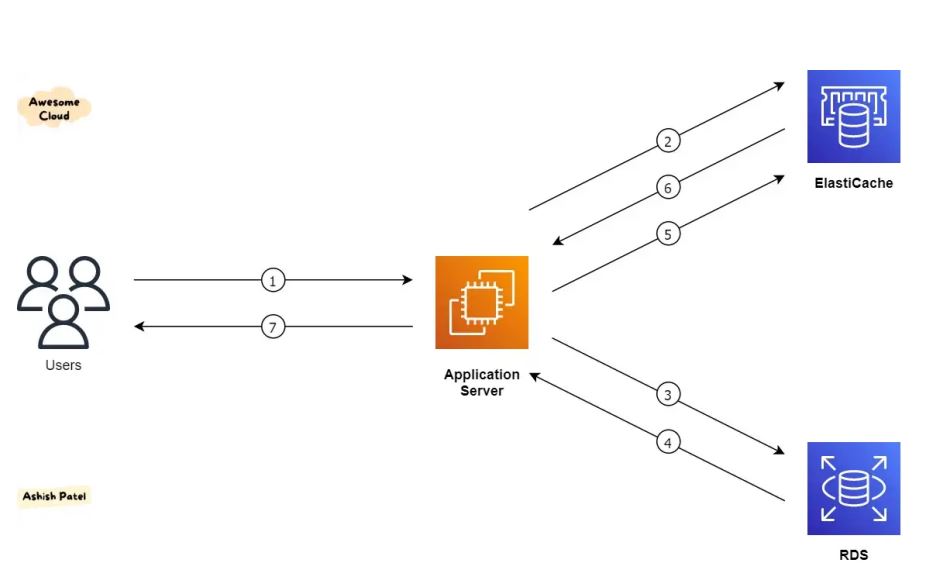
사용자가 서버에 요청을 보냈을 때 서버는 일반 DB(RDS)에 요청을 보내기 전에 Elasticache를 이용해서 값이 있는지 요청을 보낸다. 이 때 값이 있을 경우 사용자에게 바로 전달하고, 값이 없을 경우 RDS에서 조회해온 후 cache에 넣고 사용자에게 전달한다.
- Redis와 Memcached을 지원
- 캐시 노드 실패에서 자동 감지 및 복구
- 사용 예시 : 캐싱, 세션 스토어, AI ML 모델, 실시간 성이 높은 작업들(채팅)
AWS Message Queue
Queue를 사용하는 아키텍처
- 실시간 스트리밍
- 대용량 처리
- Event Driven
예시
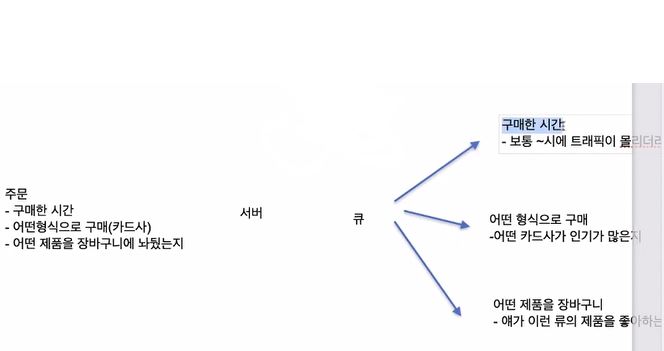
주문 데이터가 발생한 것에 대해서 여러 서버에 따라 다른 형식으로 로그를 쌓는다. 이 때 여러 서버에 보낼 때 큐를 사용해서 비동기로 보내서 서버의 부하를 줄이도록 한다. (서비스를 안정적으로 운영할 수 있게 된다.)
AWS SQS (Simple Queue Service)
마이크로서비스, 분산시스템 및 서버리스 애플리케이션을 위한 완전관리형 메시지 대기열
분류
표준 대기열
- 무제한 처리량
- 최소한 한 번 전달(여러번 전달될 수도 있음)
- 최선 노력 순서(최대한 순서를 맞추긴 하는데 보장하지는 못함)
- 사용예시 : 데이터 안에 시간이 있는 경우(로그 데이터 쌓기)
FIFO(First-In-First-Out) 대기열
- 초당 최대 300개의 메시지
- 정확히 한 번 처리
- 선입선출 전달
- 사용예시 : 한번만 처리되어야 하는 경우(메일 보내기)
DLQ(Dead Letter Queue) 지원
SQS와 Lambda를 같이 사용할 때 Lambda가 죽으면 DLQ에 해당 요청을 저장을 해놓고 나중에 다시 처리할 수 있도록 한다.
AWS Kinesis
- 모든 규모의 스트리밍 데이터를 비용 효율적으로 처리할 수 있는 핵심 기능과 애플리케이션 요구사항에 가장 적합한 도구를 선택할 수 있는 유연성을 제공한다.
- 데이터 하나하나가 중요할 때 보다 주로 대용량 및 스트리밍 데이터를 다룰 때 사용
- DLQ를 지원하지 않는다. - Lambda가 죽으면 데이터(요청)이 유실될 수 있다.
사용 예시
- 실시간으로 비디오 및 데이터 스트림을 손쉽게 수집, 처리 및 분석
- 모든 규모에서 쉽게 데이터 스트리밍
- 안정적으로 실시간 스트림을 데이터 레이크, 웨어하우스, 분석 서비스에 로드
- 스트리밍 데이터에서 실행 가능한 인사이트 확보
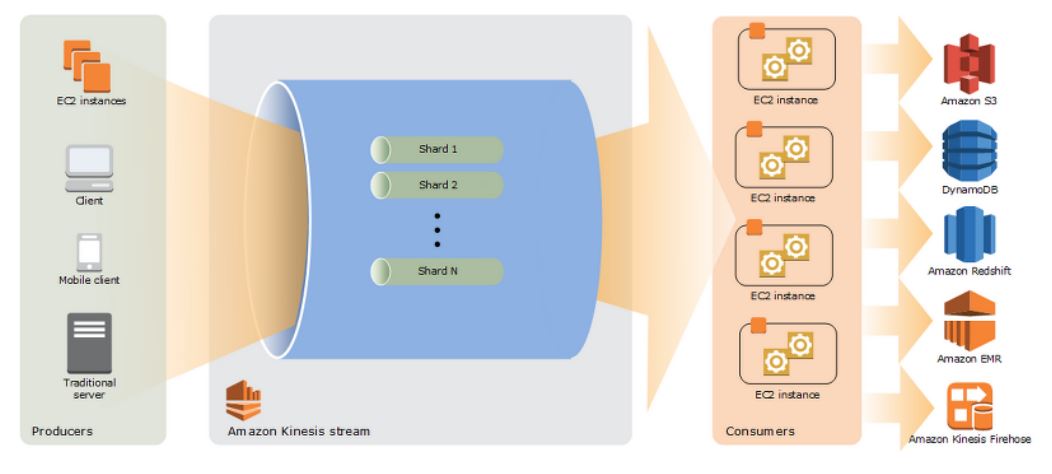
- 데이터들이 Kinesis에 들어오면 Shard 별로 분리가 된다.
- 어떤 Shard로 들어갈지는 직접 정할 수 있다.
- Shard를 많이 분배할수록 서비스를 더 빠르게 이용할 수 있다.
- Consumers를 통해 S3, DynamoDB 등 여러 대의 서버에서 Kinesis가 받은 데이터를 가져가서 처리할 수 있다. - 대용량 처리 시 유리 (SQS는 한 군데에서만 가져갈 수 있다.)
AWS SQS vs Kinesis
성능적 차이
| Kinesis | SQS | |
|---|---|---|
| Record Size | 1MB | 256KB |
| Independancy | Shard 레벨에서 나뉘어 처리 | 메시지 하나하나 별로 처리 |
| Auto-scale | 따로 설정을 해줘야 함 | 자동으로 됨 |
| Retention | 최대 7일 | 최대 14일 |
| DLQ | 지원 X | 기본 지원 |
| 잔류 | 소모되어도 Queue에 잔존 | 소모되면 Queue에서 삭제 |
- Retention : 메시지 큐에서 살아있을 수 있는 기간 (그 기간 후에 삭제됨)
사용 차이
| Kinesis | SQS |
|---|---|
| 대용량, 스트리밍 데이터에서 사용 | 메시지 하나하나에 대한 중요도가 높을 때 사용 |
출처📎
- 프리온보딩 백엔드 챌린지 12월 - 백엔드 인프라 설계 w AWS
[AWS — Difference between Amazon Aurora and Amazon RDS by Ashish Patel Awesome Cloud Medium](https://medium.com/awesome-cloud/aws-difference-between-amazon-aurora-and-amazon-rds-comparison-aws-aurora-vs-aws-rds-databases-60a69dbec41f) [Processing High Volume Big Data Concurrently with No Duplicates using AWS SQS by Engineering@ZenOfAI ZenOf.AI Medium](https://medium.com/zenofai/processing-high-volume-big-data-concurrently-with-no-duplicates-using-aws-sqs-b5a0687265f9)