
HashSet
- Set 인터페이스를 구현한다.
- 저장순서를 유지하지 않고 중복을 허용하지 않는다.
- 중복을 제거해야하면서 저장순서를 유지해야 한다면 LinkedHashSet을 사용해야 한다.
- 해싱(hashing)을 사용한다.
- 해싱 : 해시함수를 이용해서 데이터를 해시테이블에 저장하고 검색하는 기법 (해시함수는 데이터가 저장되어 있는 곳을 알려주기 때문에 다량의 데이터 중에서도 원하는 데이터를 빠르게 찾을 수 있다.)
객체 추가
객체를 추가할 때 이미 저장되어있는 요소와 중복된 요소를 추가하고자 한다면 false를 반환하여 추가에 실패했다는 것을 알린다.
객체를 추가할 때 기존에 저장된 요소와 같은 것인지 판별하기 위해
equals()와hashCode()를 호출한다.equals()와hashCode()를 목적에 맞게 오버라이딩해야 한다.
equals()
같으면 true를 반환
hashCode()
- 구현 방법
JDK1.8 미만
1
2
3
public int hashCode() {
return (name+age).hashCode();
}
JDK1.8 이상 - hash() 사용
1
2
3
public int hashCode() {
return Objects.hash(name, age);
}
- 오버라이딩 조건
동일한 객체에 대해서 동일한 int값을 반환해야 한다. (실행 시마다 동일한 int값을 반환할 필요는 없다. 단, equals 메서드의 구현에 사용된 멤버변수의 값이 바뀌지 않았다고 가정한다.)
1 2 3 4 5 6 7
Person p = new Person("Soyeon", 25); int hashCode1 = p.hashCode(); int hashCode2 = p.hashCode(); // hashCode1과 같은 값 p.age = 20; int hashCode3 = p.hashCode(); // 멤버변수를 변경한 후 이므로 다른 값이어도 된다.
equals 메서드로 비교해서 true를 얻은 두 객체에 대해 각각 동일한 int값을 반환해야 한다.
equals 메서드를 호출했을 때 false를 반환하는 두 객체는 hashCode() 호출에 대해 같은 int값을 반환하는 경우가 있어도 괜찮지만, 해싱(hashing)을 사용하는 컬렉션의 성능을 향상시키기 위해서는 다른 int값을 반환하는 것이 좋다.
TreeSet
- Set인터페이스를 구현했다.
- 중복을 허용하지 않고 정렬된 위치에 저장한다. (저장순서를 유지하지 않는다.)
- 이진 검색 트리(binary search tree)라는 자료구조의 형태로 데이터를 저장한다.
- TreeSet은 이진 검색 트리의 성능을 향상시킨 ‘레드-블랙 트리(Red-Black tree)’로 구현되어 있다.
이진 트리 구조
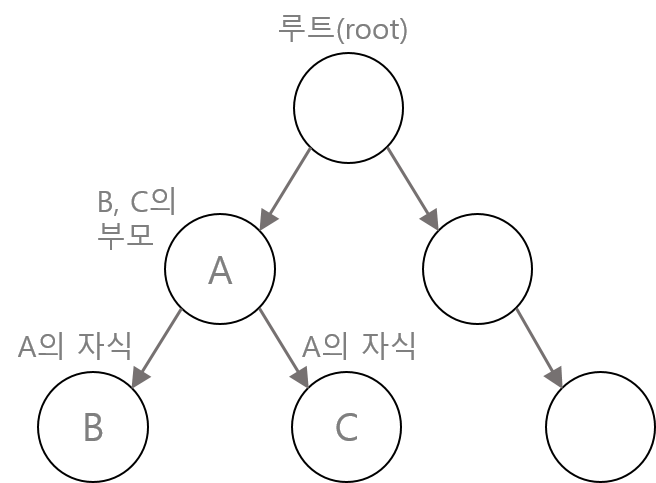
- 모든 노드는 최대 두 개의 자식노드를 가질 수 있다.
- 왼쪽 자식노드의 값 < 부모노드의 값 < 오른쪽 자식노드의 값
- ‘루트(root)’라고 불리는 하나의 노드에서부터 시작해서 확장해 나갈 수 있다.
- 위 아래로 연결된 두 노드를 ‘부모-자식관계’에 있다고 하며, 위의 노드를 부모 노드, 아래 노드를 자식 노드라고 한다.
- 노드의 추가, 삭제에 시간이 걸린다. (순차적으로 저장하지 않으므로)
- 검색(범위검색)과 정렬에 유리하다.
- 중복된 값을 저장하지 못한다.
각 노드의 데이터
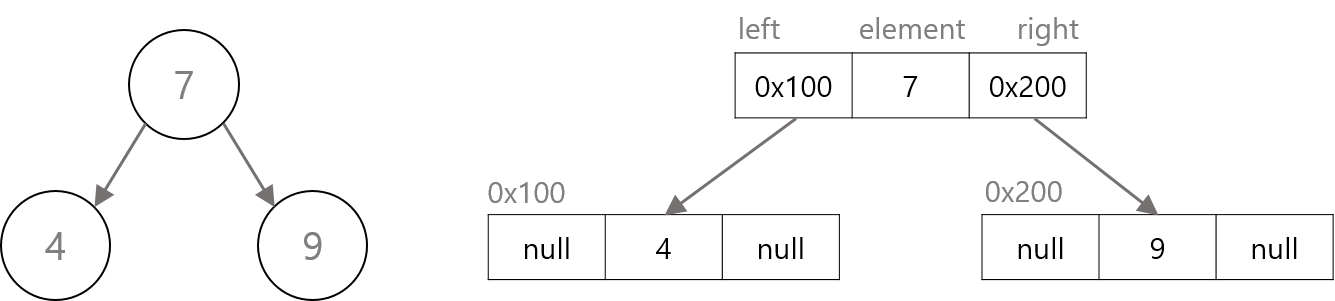
1
2
3
4
5
class TreeNode {
TreeNode left; // 왼쪽 자식노드
Object element; // 객체를 저장하기 위한 참조변수
TreeNode right; // 오른쪽 자식노드
}
노드 추가
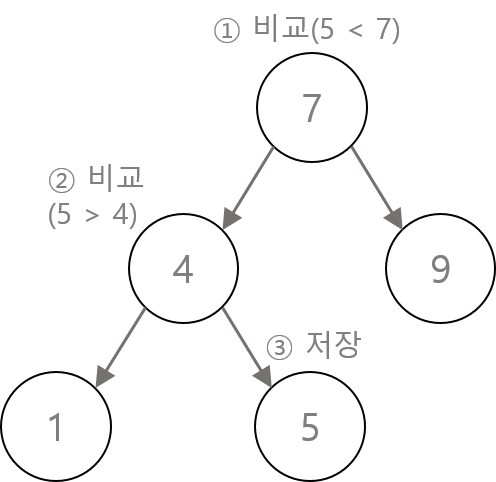
- 루트에서부터 시작해서 값의 크기를 비교하면서 트리를 따라 내려간다.
- 작은 값은 왼쪽에 큰 값은 오른쪽에 저장한다.
- 노드에 객체를 저장할 때 객체가 Comparable을 구현하던가 Comparator를 제공해서 두 객체가 비교할 방법을 알려줘야 한다. (그렇지 않으면 객체 저장 시 예외 발생)
- 오름차순으로 정렬된 데이터를 얻기 위해서는
왼쪽 노드 → 부모노드 → 오른쪽 노드순으로 읽어오면 된다.- 왼쪽 마지막 레벨이 제일 작은 값이 되고, 오른쪽 마지막 레벨이 제일 큰 값이 된다.
- 이처럼 정렬된 상태를 유지하기 때문에 배열, 링크드 리스트에 비해 단일값 검색, 범위 검색에 유리하다.
- 문자열의 경우 정렬순서는 문자의 코드값이 기준
- 오름차순 : 코드 값의 크기가 작은 순서에서 큰 순서 (공백, 숫자, 대문자, 소문자 순)
- 저장 위치를 찾아서 저장해야하고, 삭제할 경우 트리 일부를 재구성해야하므로 데이터의 추가/삭제가 링크드 리스트보다 더 오래 걸린다.
범위 검색
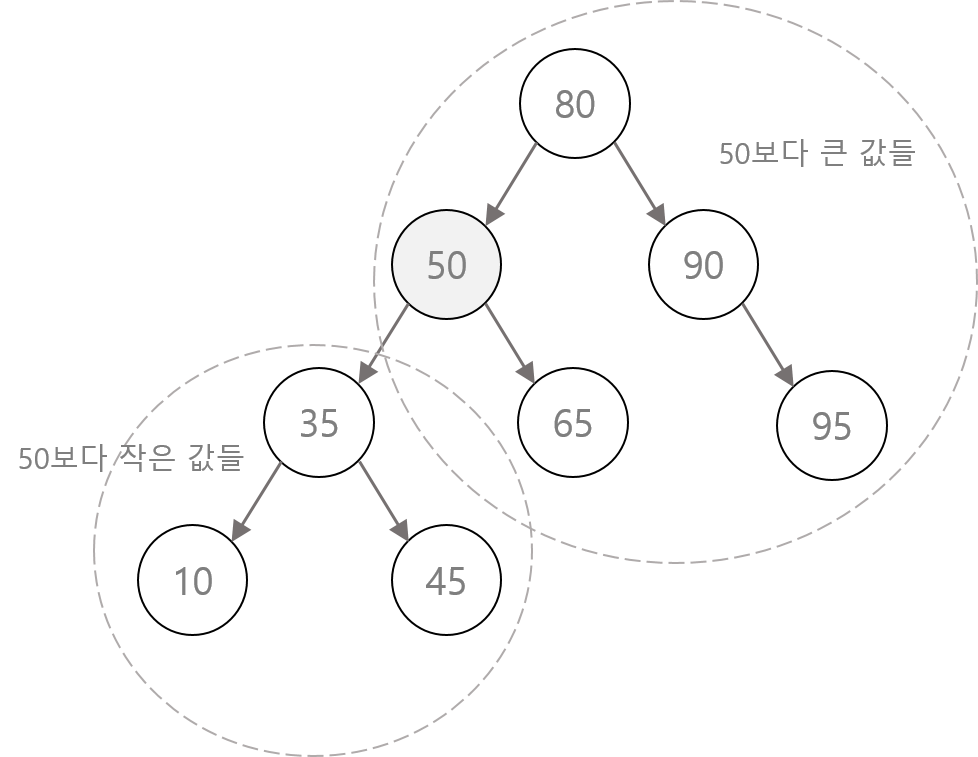
기준 값보다 작은 값 : 왼쪽 가지 아래 기준 값보다 큰 값 : 왼쪽 가지 아래 이외
1
2
3
4
5
6
7
8
9
TreeSet set = new TreeSet();
int[] scores = {80, 90, 95, 35, 45, 65, 10};
for(int i=0; i < score.length; i++) {
set.add(new Integer(score[i]));
}
System.out.prinln("50보다 작은 값 : " + set.headSet(new Integer(50)));
System.out.prinln("50보다 큰 값 : " + set.tailSet(new Integer(50)));
출처📎
- 자바의 정석